番外編:
(朝日新聞記事2011.2.11)スパコン、クイズ王に挑む(リンクが切れた場合はここをクリックしてください。ただしブラウザはIEのみ使用可)
(朝日新聞記事2011.2.17)スパコン、米のクイズ王に圧勝 本100万冊分の知識(リンクが切れた場合はここをクリックしてください。ただしブラウザはIEのみ使用可)
(情報処理学会解説記事)Watson: クイズ番組に挑戦する質問応答システム
 研究の詳細
研究の詳細
コンピュータに「せんせいになった」を入力してスペースキーを押してみると、大抵「先生になった」が表示されます。しかし、なぜ「先生になった」であって、「先生担った」にはならないのでしょうか。そう、我々人間にとってはその理由は極めて単純−−「先生担った」は正しい日本語はないからなのです。でも、コンピュータにそれを分かってもらうのはそう簡単なことではありません。
自然言語処理は、このように自然言語、すなわち人間の読み、書き、話す言葉を如何にコンピュータに分かってもらうかについての技術です。
自然言語処理はまた、インターネットを代表とする高度化情報社会の今においては、必要な情報を的確に抽出してくれたり、長い文を自動要約してくれたり、またはいろいろな質問に答えてくれるシステムの開発に大きな役割を果たしています。さらに、音声認識の後処理、日本語や英語入力の誤りチェック、外国語学習支援や作文支援などにも大きな力を発揮しています。
自然言語処理は画像処理などと並び情報処理の基幹技術です。自然言語処理はその実用性または将来性から大学のみならず、国の研究機関や企業も積極的にその研究開発に取り組んでいます。
当研究室では、自然言語処理の基礎技術から上記インターネットへの応用まで幅広い研究課題に取り組んでいます。応用課題としては、情報検索、質問応答システム、そして、情報抽出について研究開発を行っています。
インターネットは人間の知的活動のさまざまな領域に関する情報を豊富に提供してくれます。いわば、刻々と整備・更新されている知識の宝庫です。当研究室では、ユーザが知りたいこと(例えば「ホリエモンの年収はいくらですか」のような質問)をインターネットの関連サイトを即時に調べて解析し、解析した結果(答え)を素早くかつ的確に教えてくれる質問応答システムの研究開発を進めています。開発したシステムの実行例を以下の図に示す。また、システムはまもなくこのサイトで公開する予定です。性能向上などがこれからの課題ですが、みなさんは決まった形の質問文を自由に入力し本システムからどのような答えが返っ てくるかを楽しめます。

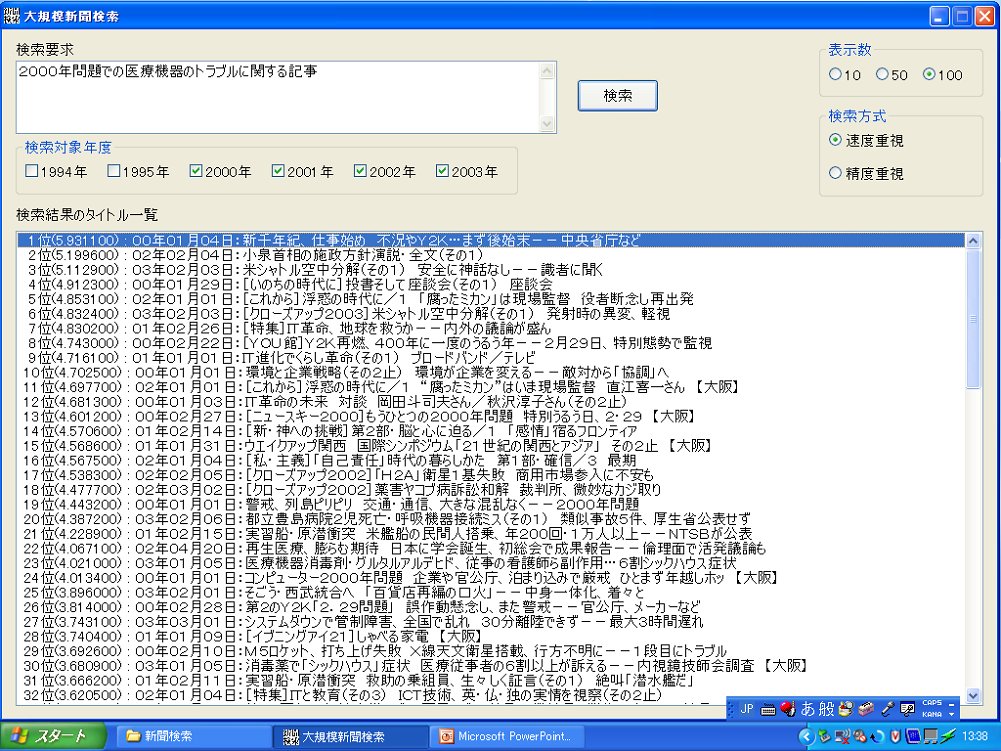
当研究室では、YahooやGoogleよりも先進的なインターネット検索エンジンを目指し研究開発を進めています。開発中のシステムは、従来のようなキーワードだけでなく、完全な日本語文の形での検索要求(下の図を参照)も受け付けます。検索要求を受け付けた後、システムに蓄えられているここ数年分の新聞データから検索要求に適合した記事群を数秒で取って来ることができます。以下、システムの実行例を示す。

学習に基づく言語処理
人間の言語能力は基本的にたくさんの実例を学ぶことによって身に付けているということから、当研究室では、主要方法の一つとして、学習に基づく言語処理のアプローチを取っています(下図)。具体的には、脳を真似しようとする立場から考案されてきたさまざまな神経回路網を主力の学習エンジンとして用い、決定木、隠れマルコフモデル、誤り駆動型書き換え規則、最大エントロピー、サポートベクターマシンなど他のさまざまな学習手法とうまく融合して、大量の言語データから必要な知識や規則を獲得し、それらの知識や規則を用いて、日本語や中国語に存在する、語義から構文までのさまざまな曖昧性を解消する基礎研究や、可視化情報検索といった高度情報化社会のニーズに答える応用研究に取り組んでいます。

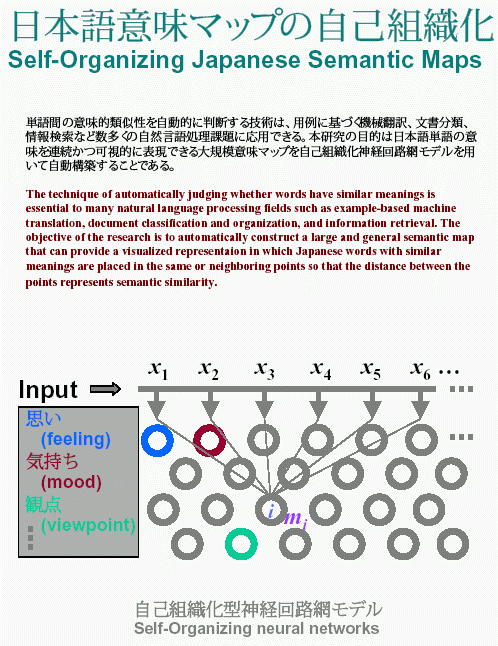
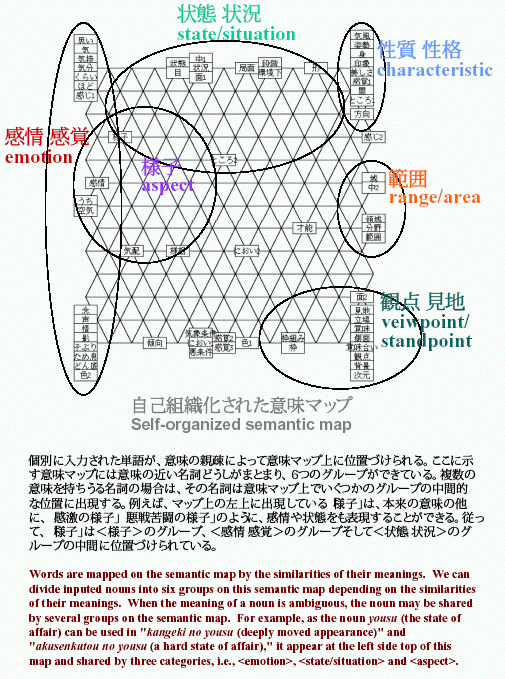
下の図は、自己組織型神経回路網に、大量の新聞データを刺激パターンとして、ただ単に繰り返して提示するだけで、神経回路網がそれらの刺激パターンに段々順応していき、意味的に近い単語どうし(つまり似た刺激パターンどうし)に近隣の神経細胞が強く反応し、似ていないパターンに互いに遠く離れている神経細胞が反応するようになっていく、単語の意味に応じた自己組織化過程のコンピュータシミュレーション結果をお示しています。このような意味マップは、多言語に拡張すれば、機械翻訳の研究に必要といされる対訳文の自動対応付けに応用できます。また、1単語を1記事と考え、その単語の共起語セットを記事内容に置き換えれば記事の自動分類や情報検索(及びそれらの可視化)にも適応できます。